INSTITUTO TECNOLÓGICO DE CERRO AZUL
Programación web



Historia de Internet
La idea revolucionaria
En 1962, como consecuencia del fortalecimiento del comunismo, las Fuerzas Aéreas de Estados Unidos pidieron a un reducido grupo de investigadores que creara una red de comunicaciones militares que pudiera resistir un ataque nuclear. El concepto de esta red se basaba en un sistema descentralizado, de manera que la red pudiera seguir funcionando aunque se destruyeran uno o varios equipos.
El modelo Baran
Paul Baran es considerado como una de las figuras clave de la creación de Internet. En 1964, él tuvo la idea de crear una red con la forma de una enorme telaraña. Se había dado cuenta de que un sistema centralizado era vulnerable, ya que si se destruía su núcleo, se podían cortar todas las comunicaciones. Por este motivo, creó un método híbrido al utilizar la topología de estrella y de malla, en el que los datos viajarían dinámicamente "buscando" la ruta más clara y "esperando" en caso de que todas las rutas estuvieran bloqueadas. Esta tecnología se denominó "conmutación de paquetes".
ARPANET
En agosto de 1969, al margen del proyecto militar, ARPA (Agencia de Proyectos de Investigación Avanzados, una división del Ministerio de Defensa de Estados Unidos) creó la red experimental ARPANET cuyo fin era conectar cuatro universidades:
-
El Instituto de Investigación Stanford,
-
La Universidad de California en Los Ángeles,
-
La Universidad de California en Santa Bárbara,
-
La Universidad de Utah.
Actualmente, ARPANET es considerada la precursora de Internet. En ese momento, ya incluía diversas características fundamentales de la red actual:
-
Uno o más núcleos de la red se podían destruir sin interrumpir su funcionamiento,
-
Los equipos podían comunicarse sin la mediación de un equipo central,
-
Los protocolos utilizados eran básicos
Correo electrónico
En 1971, Ray Tomlinson desarrolló un nuevo medio de comunicación: el correo electrónico. El contenido del primer correo electrónico fue:
QWERTYUIOP
Además, el carácter "@" ya se estaba utilizando para separar al nombre del usuario del resto de la dirección.
En julio de 1972, Lawrence G. Roberts mejoró los horizontes vislumbrados por Tomlinson y desarrolló la primera aplicación para enumerar, leer selectivamente, archivar y responder o reenviar un correo electrónico. Desde ese momento, el correo electrónico no ha cesado de crecer y se convirtió en el uso más común de Internet a comienzos del siglo XXI.
Además, en 1972 (octubre), por primera vez ARPANET se presentó al público en general con motivo de la conferencia ICCC (Conferencia Internacional en Comunicaciones por Ordenador). Por aquella época, ARPA se convirtió en DARPA (Agencia de Proyectos Avanzados de Investigación para la Defensa) y el término "internetting" se utilizó para referirse a ARPANET. Posteriormente se adoptó su forma abreviada "Internet".
Protocolo TCP
El protocolo NCP, utilizado en aquel entonces, no permitía la verificación de errores y por sistema, sólo se podía utilizar con ARPANET, cuya infraestructura estaba controlada correctamente.
Por este motivo, Bob Kahn, quien llegó a ARPA en 1972, comenzó a trabajar en la creación de un nuevo protocolo, denominado TCP, cuyo objetivo era enrutar los datos de la red al fragmentarlos en paquetes más pequeños. En la primavera de 1973, se le pidió a Vinton Cerf (que se encontraba trabajando en Stanford) que colaborara en la creación de este protocolo.
En 1976, el DoD decidió utilizar el TCP en ARPANET, compuesto por 111 equipos interconectados. En 1978, TCP se dividió en dos protocolos: TCP e IP y formaron lo que se convertiría en el conjunto TCP/IP.
DNS
El sistema de nombres DNS, utilizado actualmente, se implementó en 1984 para remediar la falta de flexibilidad inherente en archivos host, en los que los nombres de los equipos y sus respectivas direcciones se almacenaban en archivos de texto que debían actualizarse manualmente.
RFC
En 1969, Steve Crocker (que en aquel entonces se encontraba en la Universidad de California) perfeccionó el sistema "Petición de comentarios" (RFC). Este sistema consistía en un grupo de documentos en forma de memorandos que permitía a los investigadores compartir sus trabajos.
Jon Postel (6 de agosto de 1943 - 16 octubre de 1998) estuvo a cargo de administrar estos documentos hasta el día de su fallecimiento.
La World Wide Web
Para el año 1980, Tim Berners-Lee, un investigador del CERN en Ginebra, diseñó un sistema de navegación de hipertexto y desarrolló, con la ayuda de Robert Cailliau, un software denominado Enquire para la navegación.
A finales de 1990, Tim Berners-Lee terminó el protocolo HTTP (Protocolo de transferencia de hipertexto) y el protocolo HTML (Lenguaje de marcado de hipertexto) para navegar por las redes a través de hipervínculos. Así nació la World Wide Web.
Web 1.0
Nace en 1991 y su periodo acaba en 2003.
Es sin duda alguna el periodo más largo de internet y representa los orígenes de “algo” que en principio ni siquiera los creadores habrían podido imaginar su repercusión.
La web 1.0 representa la unidad de trabajo como la página web, una página donde el contenido en forma de sitios corporativos, noticias son estáticas y sólo en los últimos años de este periodo comienza a aparecer tanto los grandes Navegadores como el lenguaje HTML que hará la visualización de este contenido algo más agradable.
Las principales características son:
-
Páginas estáticas.
-
Extensiones propias de HTML introducidas por la guerra de navegadores.
-
Libros de visitas.
-
Botones “gif”.
-
Formularios HTML vía email.
-
Sin participación del usuario / visitante.
-
Páginas fijas difíciles de actualizar.
Web 2.0
A partir de 2004 hasta la actualidad se abre un nuevo concepto por el cual el diseño de los sistemas logra la conectividad de usuarios y potencian la denominada inteligencia colectiva. La participación de usuarios se hace patente.
Si en la versión anterior la mayoría de usuarios eran consumidores, en esta Web 2.0 el usuario es proconsumidor, es decir, produce contenido y a la vez lo consume.
Ejemplos:
-
Servicios web.
-
Aplicaciones web.
-
Redes sociales.
-
Wikis.
-
Blogs.
-
Podcasts.
-
Agregadores.
-
Plataformas Online.
Por supuesto, esto supuso un cambio radical a la hora de la programación y tecnologías empleadas. Se pasaba del HTML a técnicas como:
-
CSS
-
Ajax
-
Java
-
XML
Y se han realizado numerosas comparaciones entre la web 1.0 y la 2.0 (actual), algunas de las más claras serían la comparación de la Enciclopédia Británica <> Wikipedia por su grado de participación y creación de nuevos contenidos.
Web 3.0
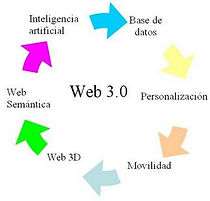
Web 3.0 es un término que se utiliza para describir la evolución del uso y la interacción en la red a través de diferentes caminos. Ello incluye, la transformación de la red en una base de datos, un movimiento hacia hacer los contenidos accesibles por múltiples aplicaciones non-browser, el empuje de las tecnologías de inteligencia artificial, la web semántica, la Web Geoespacial, o la Web 3D. Frecuentemente es utilizado por el mercado para promocionar las mejoras respecto a la Web 2.0. El término Web 3.0 apareció por primera vez en 2006 en un artículo de Jeffrey Zeldman, crítico de la Web 2.0 y asociado a tecnologías como AJAX. Actualmente existe un debate considerable en torno a lo que significa Web 3.0, y cuál sea la definición más adecuada.
La Web semántica o Web 3.0 (del inglés semantic web) es la "Web de los datos". Se basa en la idea de añadir metadatos semánticos y ontológicos a la World Wide Web. Esas informaciones adicionales —que describen el contenido, el significado y la relación de los datos— se deben proporcionar de manera formal, para que así sea posible evaluarlas automáticamente por máquinas de procesamiento. El objetivo es mejorar Internet ampliando la interoperabilidad entre los sistemas informáticos usando "agentes inteligentes". Agentes inteligentes son programas en las computadoras que buscan información sin operadores humanos.
Con la web 3.0 se busca que los usuarios puedan conectarse desde cualquier lugar, cualquier dispositivo y a cualquier momento.
Innovaciones:
Bases de datos
El primer paso hacia la "Web 3.0" es el nacimiento de la "Data Web", ya que los formatos en que se publica la información en Internet son dispares, como XML, RDF y microformatos; el reciente crecimiento de la tecnología SPARQL, permite un lenguaje estandarizado y API para la búsqueda a través de bases de datos en la red. La "Data Web" permite un nuevo nivel de integración de datos y aplicación inter-operable, haciendo los datos tan accesibles y enlazables como las páginas web. La "Data Web" es el primer paso hacia la completa "Web Semántica". En la fase "Data Web", el objetivo es principalmente hacer que los datos estructurados sean accesibles utilizando RDF. El escenario de la "Web Semántica" ampliará su alcance en tanto que los datos estructurados e incluso, lo que tradicionalmente se ha denominado contenido semi-estructurado (como páginas web, documentos, etc.), esté disponible en los formatos semánticos de RDF y OWL.
Inteligencia artificial
Web 3.0 también ha sido utilizada para describir el camino evolutivo de la red que conduce a la inteligencia artificial. Algunos escépticos lo ven como una visión inalcanzable. Sin embargo, compañías como IBM y Google están implementando nuevas tecnologías que cosechan información sorprendente, como el hecho de hacer predicciones de canciones que serán un éxito, tomando como base información de las webs de música de la Universidad. Existe también un debate sobre si la fuerza conductora tras Web 3.0 serán los sistemas inteligentes, o si la inteligencia vendrá de una forma más orgánica, es decir, de sistemas de inteligencia humana, a través de servicios colaborativos como del.icio.us, Flickr y Digg, que extraen el sentido y el orden de la red existente y cómo la gente interactúa con ella.
Web semántica y SOA
Con relación a la dirección de la inteligencia artificial, la Web 3.0 podría ser la realización y extensión del concepto de la “Web semántica”. Las investigaciones académicas están dirigidas a desarrollar programas que puedan razonar, basados en descripciones lógicas y agentes inteligentes. Dichas aplicaciones, pueden llevar a cabo razonamientos lógicos utilizando reglas que expresan relaciones lógicas entre conceptos y datos en la red. Sramana Mitra difiere con la idea de que la "Web Semántica" será la esencia de la nueva generación de Internet y propone una fórmula para encapsular Web 3.0
Este tipo de evoluciones se apoyan en tecnologías de llamadas asíncronas para recibir e incluir los datos dentro del visor de forma independiente. También permiten la utilización en dispositivos móviles, o diferentes dispositivos accesibles para personas con discapacidades, o con diferentes idiomas sin transformar los datos.
Para los visores: en la web, xHTML, JavaScript, Comet, AJAX, etc.
Para los datos: Lenguajes de programación interpretados, Base de datos relacional y protocolos para solicitar los datos.
Evolución al 3D
Otro posible camino para la Web 3.0 es la dirección hacia la visión 3D, liderada por el Web 3D Consortium. Esto implicaría la transformación de la Web en una serie de espacios 3D, llevando más lejos el concepto propuesto por Second Life. Esto podría abrir nuevas formas de conectar y colaborar, utilizando espacios tridimensionales. Ya hoy en día vemos que se realizan películas en 3D para el cine, que van sustituyendo al sistema 2D.
bibliografia
http://www.facilware.com/la-evolucion-de-la-web-1-0-2-0-y-3-0.html
http://julionica.udem.edu.ni/wp-content/uploads/2014/01/Evolucion_Web.pdf
http://www.estudioseijo.com/noticias/web-10-web-20-y-web-30.htm